매일 세상에 엄청난 양의 시각적 데이터가 생성되고 있음.
이에 많은 양의 시각 데이터를 이해하고 분석하기 위해 오랜 시간 동안
자동으로 이를 분석하는 알고리즘을 개발하려고 노력해왔다.
이 강의에서는 이런 컴퓨터 비전의 역사를 소개함으로써
컴퓨터 비전 분야는 아직 더 많은 연구가 필요하며, 활용범위도 무궁무진하다.

컴퓨터비전의 역사 (A brief history of computer vision)
- 5억 4300만년 전, 천만년 동안 동물의 종 수가 폭발했다는 사실을 알아냄 (몇 개에서 수 십만 개로 늘어남)
= 진화론의 빅뱅 "Evolution's BigBang"
이때, 동물은 최초의 눈이 발달했고 시각을 사용하기 시작함으로써 폭발적인 종분화 단계가 시작!
=> 시각은 동물, 특히 지능이 뛰어난 동물(인간)에게 매우 중요하다.

1. 포유류의 시각 처리 메커니즘
▶ Hubel과 Wiesel의 고양이 뇌 연구 (=인간과 시각적 메커니즘이 비슷함)
: 일차 시각 피질 부분에는 다양한 세포가 존재하지만, 가장 중요한 세포 중 하나는 특정 방향으로 이동할 때 방향의 가장자리(edges)에 반응하는 단순 세포들이라는 것을 알게 됨
=> 초기의 시각적 처리가 단순한 구조로 시작하여 점점 복잡해지는 것 발견!
시각 처리의 초기단계는 edges와 같은 단순한 구조와 밀접한 관련이 있다.
컴퓨터 비전의 역사는 60년대 초 시작됨

눈에 보이는 것을 기하학적 모양으로 단순화
"The Summer Vision Project" (MIT 여름 프로젝트)
ㄴ 목표 : 여름 동안 대부분의 시각 시스템을 구현하겠다.
50년이 지난 지금도 컴퓨터 비전 분야는 수많은 연구가 진행되고 있고,
인공지능에서 가장 중요하고 가장 빠르게 성장하는 분야 중 하나로 성장함.
2. 이미지의 최종적인 Full 3D 표현
👨🏫 David Marr - (MIT 비전 과학자)
: 70년대 후반, 자신이 생각하는 비전 무엇?, 어떻게 나아가야 하는지, 어떻게 시각적 세계를 인식할 수 있도록 하는 알고리즘 개발해야 하는지에 대한 영향력 있는 책 저술.

우리 눈에 인식된 이미지를 최종 3d 표현에 도달하기 위해 여러 프로세스(3단계) 거쳐야 한다 주장.
① primal sketch - edges(모서리), bars(막대), ends(끝), virtual lines(가상의 선), curves(커브), boundaries(경계) 표현되는 과정
② two-and-a-half d sketch - surfaces(표면), depth information(깊이 정보), layers(레이어), discontinuities of visual scene(시각적 장면의 불연속성) 같은 것들을 종합
③ 3D model - hierrarchically organized in terms of surface and volumtric primitives
모든 것을 모아서 표면 ~ 체적 초기단계 등의 계층적으로 구성된 3D 모델 만들어 냄
=> 시각이 무엇인지에 대한 매우 이상적인 사고 과정이었고,
이러한 사고방식은 실제로 수 십 년 동안 컴퓨터 시각을 지배해 옴
(시각 정보를 분해하는 방법에 대해 생각할 수 있는 매우 직관적인 방법)
3. Generalized Cylinder & Pictorial Structure
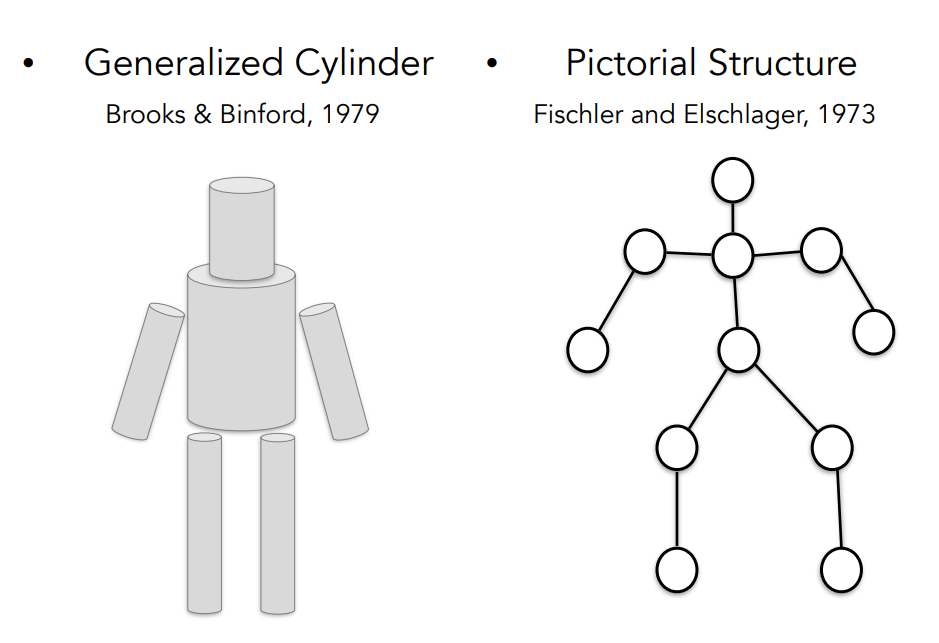
70년대 사람들 👥 :
Q. 단순한 블록 세계를 넘어서 어떻게 실제 세계의 물체를 인식하거나 표현 하기 시작할 수 있을까 ❓
ㄴ 사용 가능한 데이터 거의 없는 시대, 컴퓨터 매우 느리고 PC도 많이 X
but, 컴퓨터 과학자들은 어떻게 물체를 인식하고 표현할 수 있을지 방법에 대해 고민하기 시작함!
→ Stanford, SRI에서 과학자들이 비슷한 아이디어 제안함
① Generalized Cylinder(일반화된 실린더) : 원통 모양으로 표현
② Pictorial Structure(그림 구조) : 주요 부위, 관절로 표현
=> 모든 객체는 단순한 기하학적 형태로 구성되어 있다.
복잡한 객체인 사람을 단순한 모양, 기하학적 구성을 이용해서 표현함
단순한 모양과 기하학적 구성을 이용해서 복잡한 객체를 단순화시키는 방법은 수년간 다른 연구에 多영향을 끼침.
4. Object Recognition

80년대 David Lowe : 단순한 세계 구조에서 시각적 세계를 재구성하고 인식하는 방법 고민
ㄴ 선(lines)과 가장자리(edges), 대부분의 직선(straight lines)과 이의 조합을 구성하여 면도기를 인식함.
- 60-80년대 컴퓨터 비전의 작업이 무엇인지 생각하기 위해 많은 노력을 기울였으며
객체 인식(object recognition) 문제 해결하기 어려움
∴ object segmentation 먼저 수행해보자! ⬇

▶ Image Segmentation
: 이미지를 가져와 픽셀을 의미 있는 영역으로 그룹화하는 작업
픽셀을 모아놔도 그게 사람이란 걸 인식할 수 없을 수도 있지만,
적어도 배경에서 사람에 해당하는 모든 픽셀들은 추출할 수 있다.

객체 분할을 하기 위해 그래프 이론이 도입, face detection에서 활용
▶ face detection
: 1999년 ~ 2000년 사이 인간에게 가장 관심의 대상이었던 얼굴 인식 분야의 기계 학습(ML) 기법.
(->특히, 통계적 학습 기법이 탄력을 받기 시작.)
Paul CIola & Michael Jones - AdaBoost 알고리즘을 사용한 실시간 얼굴 감지
ㄴ 논문 발표 5년 후 2006년, Fujifilm은 실시간 얼굴 감지기가 내장된 최초 디지털카메라 출시함
5. 특징 기반 객체 인식 알고리즘
90년 후반 ~ 2000년대 초반까지 10년 동안 가장 영향력 있는 사고방식 중 하나
= 특징 기반 객체 인식(feature based object recognition)

▶ David Low - SIFT features
: 객체 전체를 매칭 시키는 것은(정지 표지판 두 개를 매칭 시키는 것)
카메라 각도, 폐색, 시점, 조명 및 본질적인 변화로 인해 모든 종류의 변화가 있을 수 있기 때문에 매우 어려움
but
> 객체의 특징 중 일부는 변경 사항(다양한 변화)에 더 강인하고 불변하다는 점 발견
객체인식은 객체에서 중요한 특징을 찾아낸 다음 비슷한 객체와 특징을 매칭 시켜봄
정지 표지판에서 수십 개의 SIFT 특징이 식별, 다른 정지 표지판의 SIFT 형상과 일치되는 것을 보여줌
> 이미지에서 일부 SIFT 특징 추출 → 다른 이미지에서 특징을 추출하여 식별하고 매칭

이미지의 특징을 사용하면서 컴퓨터 비전은 한 단계 더 나아가 전체론적 장면을 인식하기 시작함
> 이미지의 특징 활용을 통해 발전하고 이미지 전체를 인식하기 시작
Spatial Pyramid Matching 알고리즘의 예시
: 이미지의 특징들이 장면이 풍경인지 부엌 또는 고속로도 등 어떤 유형인지 단서를 줄 수 있다는 것.
> 특징이 단서를 제공
> 이미지 내의 여러 부분과 여러 해상도에서 추출한 특징을 하나의 기술자로 표현하고
그 위에 Suppot Vector Algorithm 적용함
-> 사람인식 연구로 이어짐

보다 사실적인 이미지에서 인체를 구성하고 인식할 수 있는 방법 (연구)
① Histogram of Gradients
② Deformable Part Models(변형 가능한 부품 모델)
시대가 변하면서 인터넷 성장으로 디지털카메라는 컴퓨터 비전을 연구하기 위해 점점 더 나은 데이터를 갖게 됨
6. Benchmark Dataset
2000년대 초반에 객체인식의 과정을 측정할 수 있게 해주는 벤치마크 데이터셋(Benchmark Dataset)을 갖기 시작함

PASCAL VIsual Object Challenge : 가장 영향력 있는 벤치마크 데이터셋 중 하나,
20개의 객체 클래스로 구성된 데이터 세트
ImgaeNet 프로젝트 :
① 모든 객체의 세계를 인식하고 싶다 (세상 모든 이미지 분류)
② ML으로 과적합이라는 병목 현상을 극복하기 위해(기계학습의 Overfiting 문제 극복)
(22K categories and 14M images)
- 당시 AI 분야에서 생산된 거대하고 가장 큰 데이터셋
"ImageNet Large-Scale Visual Recognition Challenge " - 국제 과제 시작
1000 object classes + 1,431,167 images
컴퓨터 비전 알고리즘에 대한 이미지 분류 인식 결과를 테스트함


2010년~2015년까지 이미지 분류 결과 요약 (x축 : 연도, y축 : 오류율)
-> 처음 2년 동안 오류율 약 25% 맴돌았지만,
CNN의 도입으로 2012년 오류율을 16.4%로 급격히 감소되어 사람보다 낮아지기 시작.
⬇
⭐CNN(컨볼루션 신경망 모델)
1988년 이미지에서 문자를 인식하기 위해 구축됨
ㄴ 자연어 처리 및 음성인식과 같은 다른 여러 비슷한 분야에서 엄청난 능력을 보여줌 (딥러닝)
'Study > CS231n' 카테고리의 다른 글
| [CS231n-Lecture 3] Loss Functions and Optimization (0) | 2023.05.23 |
|---|---|
| [CS231n-Lecture 2] Image Classification (0) | 2023.05.18 |


댓글